Overview

Given a reference image and a driving video, EMOSH achieves high-fidelity, mesh-guided expressive human animation while disentangling expressive motion from body shape.
Given a reference image and a driving video, EMOSH achieves high-fidelity, mesh-guided expressive human animation while disentangling expressive motion from body shape.
High-fidelity and expressive controllable human animation is essential for content creation and digital avatar applications. However, existing methods face a dilemma between expressiveness and disentanglement. Mainstream 2D pose-conditioned approaches suffer from "motion-shape entanglement", leading to the leakage of the driving subject's body shape. Conversely, methods relying on 3D priors (e.g., SMPL) achieve geometric disentanglement but struggle to capture facial expressions and complex gestures, resulting in rigid animations. To this end, we propose EMOSH, a novel framework for high-fidelity controllable human video generation. First, an Expressive Human Model (EHM) is introduced as the core control representation. By explicitly disentangling shape and pose parameters, we fundamentally resolve the body shape leakage issue. Alongside this, a robust motion tracker is designed to accurately estimate EHM parameters from video. Second, we propose a Coarse-to-Fine Hybrid Motion Injection strategy, enabling more fine-grained control over expressions and gestures. Furthermore, we introduce a Spatially-Aligned Conditioning mechanism to bridge the domain gap between training and inference, improving identity consistency. Extensive experiments demonstrate that EMOSH outperforms previous methods in both self-driven and cross-driven scenarios.
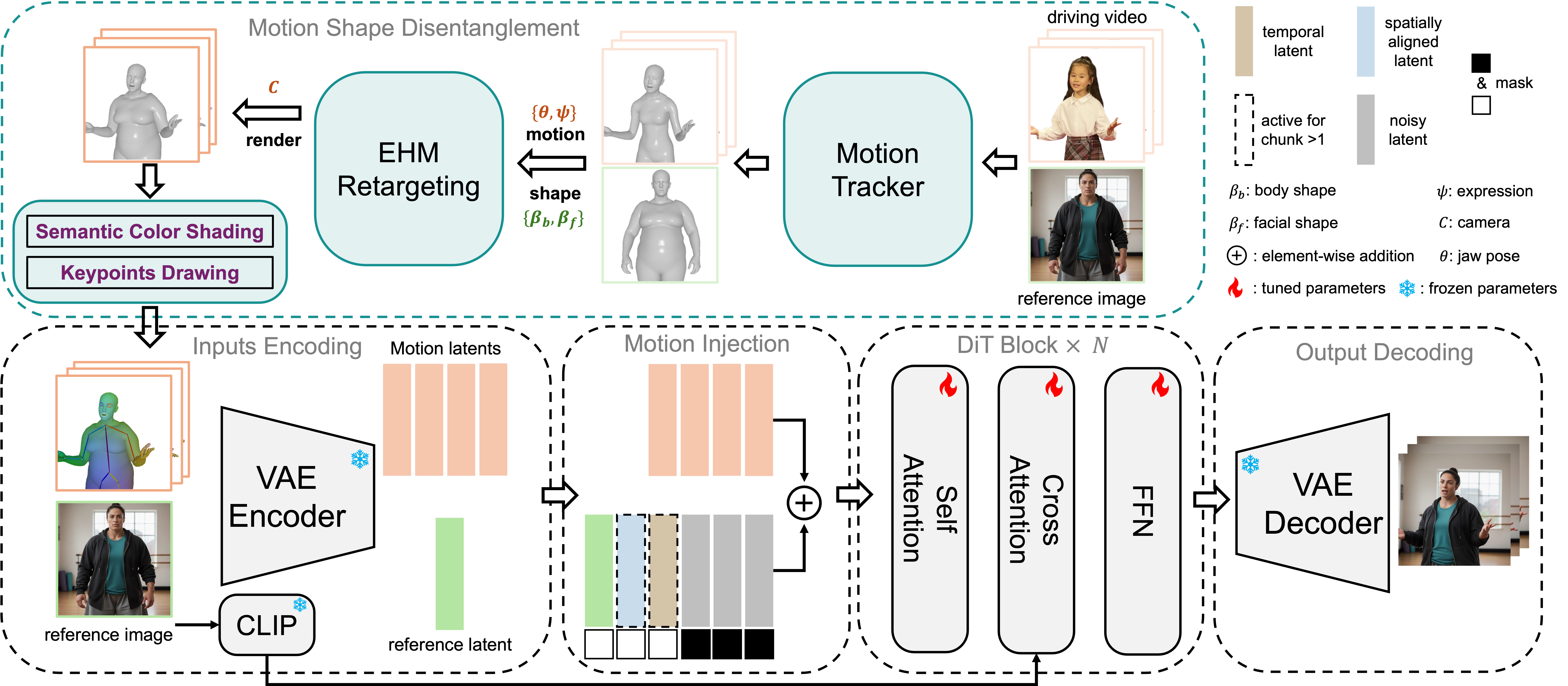
The overall pipeline of EMOSH. Given a reference image and a driving video, we first track the EHM parameters. The motion features are injected in a coarse-to-fine manner through the Hybrid Motion Injection module. Spatially-Aligned Conditioning bridges the domain gap to ensure identity consistency.
@inproceedings{zhang2026emosh,
title={EMOSH: Expressive Motion and Shape Disentanglement for Human Animation},
author={Zhang, Dongbin and Liu, Hao and Dai, Binquan and Chen, Kangjie and Wang, Chuming and Li, Chen and LYU, Jing and Wang, Haoqian},
booktitle={European Conference on Computer Vision (ECCV)},
year={2026}
}